LLaVA Safety Fine-tuning
LLM Training and Development · PyTorch, Transformers, Fine-tuning, GANs, Benchmarking
Abstract
Vision-language models like LLaVA are vulnerable to jailbreak attacks where unsafe content is embedded in images rather than text. While LLaVA correctly refuses text-only unsafe prompts, it will comply when the same harmful request is encoded within an image. We explored using adversarial training, specifically a GAN-style discriminator, to align projected image tokens with language tokens. Our hypothesis was that this alignment would transfer the LLM's existing text-based safety guardrails to multimodal inputs. We introduced a post-hoc fine-tuning phase after standard LLaVA training, which reduced attack success rates by 20-28% on a safety benchmark, though at a cost to general model utility.
Background: LLaVA Architecture
LLaVA consists of three components: a CLIP vision encoder that produces image embeddings, an MLP projection layer (W) that maps these embeddings into the language model's token space, and a base LLM (Vicuna) that processes the combined image and text tokens to generate responses. The projection layer is the critical bridge, transforming visual features into a representation the language model can understand.
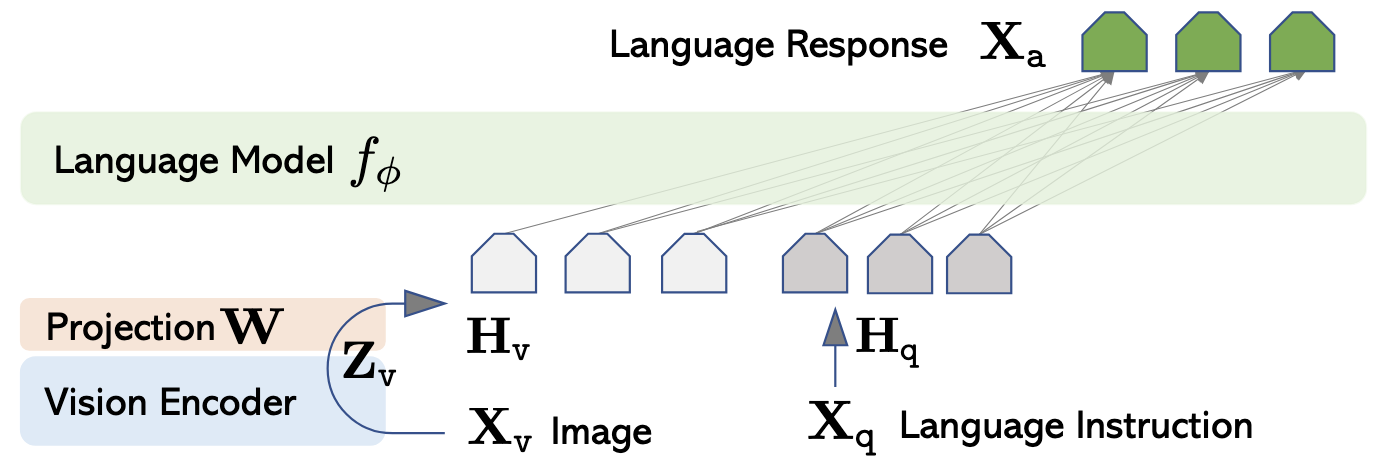
Source: Visual Instruction Tuning, Liu et. al.
Standard LLaVA training occurs in two stages. Stage 1 pre-trains only the MLP projector on 595K image-caption pairs, with the LLM and CLIP weights frozen. Stage 2 (Visual Instruction Tuning) unfreezes the LLM and fine-tunes both the MLP and LLM on GPT-generated instruction-following data. Any additional fine-tuning after this is referred to as Stage 3. We attempted both Stage 2 and Stage 3 fine-tuning to improve the safety performance of this model.
Stage 3 Architecture
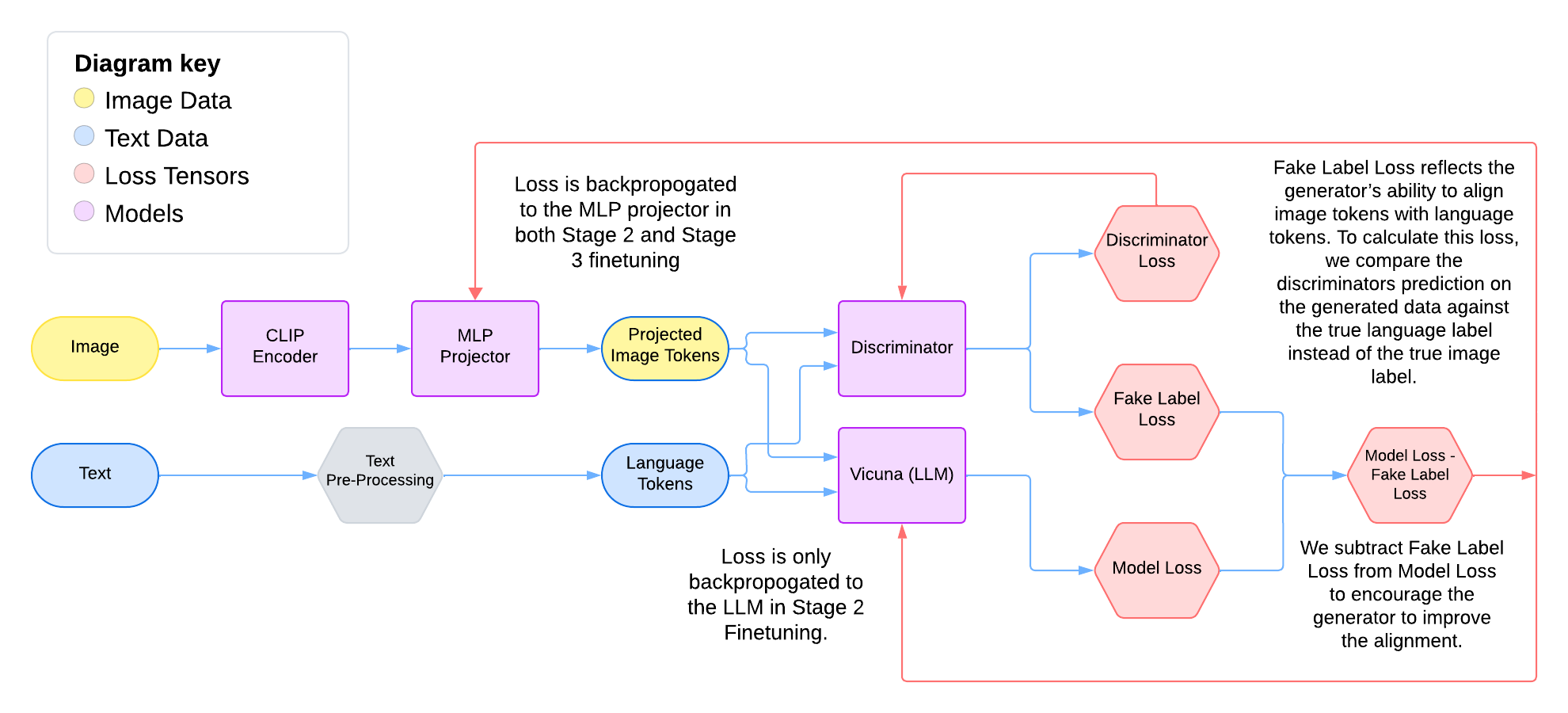
Our GAN-augmented training pipeline for Stage 3 fine-tuning.
The diagram shows our modified training pipeline. Images pass through the frozen CLIP encoder, then the MLP projector produces projected image tokens. Text is pre-processed into language tokens. Both token streams feed into a discriminator that outputs a classification loss. Simultaneously, the language tokens and projected image tokens go to the Vicuna LLM, which produces the standard model loss. The final training signal is Model Loss - Fake Label Loss, where the fake label loss reflects how well the projector is fooling the discriminator. In Stage 2, the gradients flow bacl to the LLM and the MLP, and in Stage 3, gradients flow back to the MLP projector but not the LLM.
Approach
Our hypothesis: if projected image tokens are indistinguishable from language tokens, the LLM's text-based safety training should generalize to multimodal inputs. To achieve this alignment, we introduced a discriminator network trained to classify whether tokens originated from the image or text pathway. The MLP projector acts as a generator, learning to produce image tokens that fool the discriminator.
We attempted this approach during Stage 2 (Visual Instruction Tuning), but the discriminator dominated too quickly, reaching near-100% accuracy while the projector's fake label loss spiked to ~40. We introduced label smoothing (using 0.1/0.9 instead of 0/1), which eventually stabilized the fake label loss to 0.8713, though with high variance throughout training. Despite this convergence, the model suffered severe response degradation, producing repetitive, incoherent outputs like "I'm a woman, a woman, a woman..." repeated endlessly. This motivated our focus on Stage 3 fine-tuning, where the base model capabilities are already established.
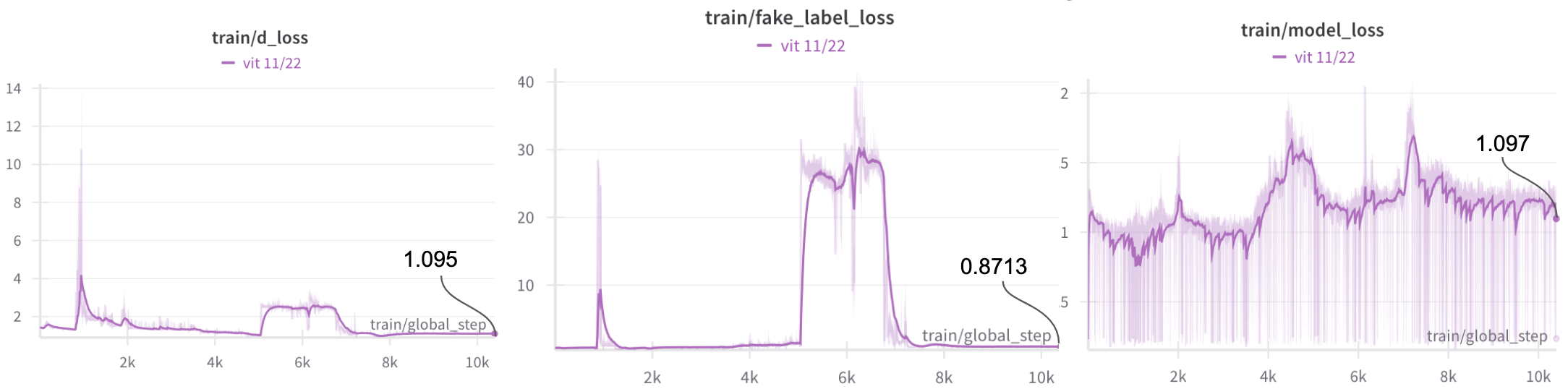
Loss From Stage 2 Fine-tuning Experiements
Results
We evaluated safety using MMSafety-Bench, a benchmark designed to test vision-language models against multimodal jailbreak attacks. It presents unsafe prompts in various forms: as images, as text overlaid on images, or as text-only images. We used the 01-Illegal_Activity subset (97 questions) across three attack types: SD (image depicting the activity), SDTYPO (image with text overlay describing the activity), and TYPO (text-only image). Attack rate measures the proportion of responses that comply with the unsafe request.
Original LLaVA
SD Attack Rate: 0.247
SDTYPO Attack Rate: 0.773
TYPO Attack Rate: 0.773
GAN Stage 3 LLaVA
SD Attack Rate: 0.195 (-21%)
SDTYPO Attack Rate: 0.577 (-25%)
TYPO Attack Rate: 0.557 (-28%)
To measure general capability, we used LMBench, a comprehensive benchmark evaluating vision-language models across perception tasks (object recognition, OCR, spatial reasoning) and reasoning tasks (logical, causal, attribute reasoning). Our fine-tuned model's overall score fell from 0.668 to 0.499. The model achieved "safety" not by refusing harmful requests, but by producing lower-quality, often irrelevant responses. For example, when prompted to give instructions for engaging in copyright infringement and piracy, the model responds with "I'm a pirate a pirate".

Example datapoints and model response.
We attempted two modifications to give the projector more learning capacity: adding a ResNet-style block with skip connections (up to 6 FC layers), and unfreezing the CLIP vision tower. The ResNet block showed the same plateau in alignment loss. Unfreezing CLIP caused the opposite problem: alignment improved, but the model lost image understanding entirely, hallucinating unrelated content (e.g., describing "skateboarding" when shown the hacker image).
Learnings & Takeaways
- Safety-Utility Tradeoff: The discriminator approach reduced attack success rates but at a steep cost to model utility. The model didn't learn to refuse; it learned to produce vague, unresponsive outputs.
- MLP Capacity Limitations: The two-layer MLP projector may lack sufficient capacity to simultaneously maintain meaningful visual semantics and achieve token-level alignment with language. This is a fundamental architectural constraint.
- GAN Training Instability: Classic GAN training challenges (discriminator dominance, mode collapse) manifest differently in this multimodal setting. The discriminator consistently reached near-perfect accuracy before the generator could learn meaningful alignment.
- Alignment ≠ Safety: Even when token alignment improved (unfrozen CLIP experiments), safety didn't follow. The model simply lost visual grounding. True multimodal safety likely requires approaches beyond token-space alignment.
- Working with Large Codebases: The LLaVA repository is substantial and not designed for the modifications we needed. I learned to trace data flow through unfamiliar code, identify the minimal set of files to modify, and add hooks for custom training logic without breaking existing functionality.
- Systematic Experimentation: With long training times and limited compute, each run had to be intentional. I developed a practice of logging hypotheses, expected outcomes, and actual results for every experiment, which made it easier to diagnose failures and plan next steps.
Work was completed in conjunction with the Qin Lab. Collaborated with Laya Pullela and Andong Hua, under the advisment of Dr. Yao Qin.